
AI Ethics Brief #64: Community well-being through data sharing, NIST proposal for bias mitigation, and more ...
Would you be comfortable being interviewed by an AI system?

Welcome to another edition of the Montreal AI Ethics Institute’s weekly AI Ethics Brief that will help you keep up with the fast-changing world of AI Ethics! Every week we summarize the best of AI Ethics research and reporting, along with some commentary. More about us at montrealethics.ai/about.
⏰ This week’s Brief is a ~12-minute read.
Support our work through Substack
💖 To keep our content free for everyone, we ask those who can, to support us: become a paying subscriber for as little as $5/month. If you’d prefer to make a one-time donation, visit our donation page. We use this Wikipedia-style tipping model to support the democratization of AI ethics literacy and to ensure we can continue to serve our community.
*NOTE: When you hit the subscribe button, you may end up on the Substack page where if you’re not already signed into Substack, you’ll be asked to enter your email address again. Please do so and you’ll be directed to the page where you can purchase the subscription.
This week’s overview:
✍️ What we’re thinking:
How data governance technologies can democratize data sharing for community well-being
🔬 Research summaries:
“A Proposal for Identifying and Managing Bias in Artificial Intelligence”. A draft from the NIST
📰 Article summaries:
How TikTok’s hate speech detection tool set off a debate about racial bias on the app
We tested AI interview tools. Here’s what we found.
How Humans Can Force the Machines to Play Fair
America's global leadership in human-centered AI can't come from industry alone
But first, our call-to-action this week:
Follow us on Twitter and LinkedIn if you haven’t yet - we publish findings from our community engagements, our research work, news on our upcoming programs, funding opportunities, and more!

✍️ What we’re thinking:
From the Founder’s Desk:
How data governance technologies can democratize data sharing for community well-being
Data sharing efforts to allow underserved groups and organizations to overcome the concentration of power in our data landscape. A few special organizations, due to their data monopolies and resources, are able to decide which problems to solve and how to solve them. But even though data sharing creates a counterbalancing democratizing force, it must nevertheless be approached cautiously. Underserved organizations and groups must navigate difficult barriers related to technological complexity and legal risk. To examine what those common barriers are, one type of data sharing effort—data trusts—are examined, specifically the reports commenting on that effort. To address these practical issues, data governance technologies have a large role to play in democratizing data trusts safely and in a trustworthy manner. Yet technology is far from a silver bullet. It is dangerous to rely upon it. But technology that is no-code, flexible, and secure can help more responsibly operate data trusts. This type of technology helps innovators put relationships at the center of their efforts.
To delve deeper, read the full paper here.

🔬 Research summaries:
“A Proposal for Identifying and Managing Bias in Artificial Intelligence”. A draft from the NIST
What does bias in an AI system look like? Is it obvious? How can we mitigate such threats? The NIST provides a 3-stage framework for mitigating bias in AI, with it being seen as key to building public confidence in the technology. Not only can such mitigation help us better reduce the effects of AI, but it can also help us better understand it, and the NIST wants to do just that.
To delve deeper, read the full summary here.

📰 Article summaries:
How TikTok’s hate speech detection tool set off a debate about racial bias on the app
What happened: TikTok is under fire again (as covered in a previous newsletter where it involuntarily changed people’s faces) for flagging content that disproportionately impacts Black creators. The creator featured in the article mentions how while editing his bio on the platform, his content was flagged as inappropriate for including phrases like “Black Lives Matter.” Phrases like “white supremacy” didn’t have a similar effect. The creator called for strikes and his videos have had more than a million views with fellow Black creators understandably agitated about disproportionate harm. The company explained that such content wasn’t against policy but their content moderation systems needed improvement to address these challenges.
Why it matters: In a COVID-19 world where a lot of activism is taking place online, such incidents impact historically marginalized people even more by stripping away their ability to organize and express their views. More so, it showcases how current automated systems for content moderation are quite brittle and unable to handle variances in the text where seemingly inappropriate content might actually be used to highlight and respond to key issues.
Between the lines: With the rise of people using social media platforms, human content moderation is only going to decrease over time since it is infeasible to check all the content that goes up on these platforms every minute. We need to have research into more robust automated methodologies and rely on community-driven moderation as an intermediate to still have some human-in-the-loop elements.
We tested AI interview tools. Here’s what we found.
What happened: With a lot of upheaval in the job market since the start of the pandemic, and limited staff capacities on the recruitment side of things for companies, many have resorted to the use of automated hiring tools. The authors of the article put two such systems to the test, CuriousThing and MyInterview to gain an understanding on how good they are in meeting their claims. To their disappointment and no surprise, they found these two tools to be opaque in what they evaluated. As an example, even when reading out paragraphs in German, the tool determined that the interviewee, one of the authors, was quite fluent in English. It also evaluated them on the Big Five personality traits and other attributes with varying results.
Why it matters: These tools are touted as a way to reduce bias in the hiring process and often the results from such tools are not the only data points in hiring decisions. But, they have the potential to skew the process, especially when they have glaring flaws and high sensitivity in how they evaluate some of these psychological traits using things like the intonation of someone’s voice rather than the content of what they are saying.
Between the lines: While the founder of the company defended that the system is not meant to be used with German and hence the flawed results, it still raises an interesting question on what the degree of robustness of these systems is, particularly when they are used in the wild, as opposed to a controlled experiment in this article, where there might not be an opportunity to review how a certain person responded. This can lead to pre-emptive dismissal in a large pool of applicants in the interest of expediency, particularly affecting those who don’t fit the mold that is determined to be ideal by the automated system.
How Humans Can Force the Machines to Play Fair
What happened: In this insightful interview with the inventor of the notion of differential privacy, we learn about the new challenges that Dwork is embarking on in her recent work. Tackling fairness in AI-infused systems, Dwork talks about her work titled “Fairness through Awareness” which takes into account both individual and group fairness and how to achieve both. She also talks about how this is a much more difficult challenge compared to her work in privacy but advocates taking a “sunshine” approach to the research work in this space. The article also has several great examples of how applying individual fairness isn’t enough and how her experience with piano practice reinforced the importance of considerations for fair affirmative action to achieve group fairness.
Why it matters: The field of AI ethics is inundated with work on how to best achieve fairness in machine learning. Yet, a lot of it struggles to articulate how to account for tradeoffs that are bound to occur when offering preferential treatment to some over others in the interest of achieving fairness. Dwork’s work and her history in providing clear metrics and methodologies for addressing challenges in achieving more responsible statistical systems is a good precedent and beacon for us to make meaningful progress in this space.
Between the lines: Bias and fairness are extremely challenging concepts when it comes to machine learning because they don’t have clear metrics as is the case with privacy where we are fairly certain of what the outcomes need to be. In this case, there is widespread disagreement even about what fair outcomes look like presenting us with graver challenges. Work that claims to provide easy solutions is certainly something to guard against, especially in the face of this space becoming commercialized with startups and tools being offered that address, or worse “fix”, bias in machine learning.
America's global leadership in human-centered AI can't come from industry alone
What happened: Li, one of the people behind the famed ImageNet dataset and the co-Director of the Stanford HAI center talks about her work on the National AI Research Resource Task Force. As a part of this work, they are seeking to realize the vision of human-centered AI by democratizing access to AI systems and education to build capacity in the ecosystem for more people to build these systems. This will be supported through the construction of a National Research Cloud with the goal of making compute and data storage resources available to a wider set of people. There is vast inequity between those who are backed by large industrial and academic labs and those who are not in terms of the research work that they can carry out in the space, something that we have highlighted in our work here as well.
Why it matters: To achieve more responsible AI systems as well, widespread access to the necessary underlying infrastructure to run experiments and do research will be essential, quite in line with the mission of the Montreal AI Ethics Institute as well. More importantly, with dedicated resources being allocated by the federal government and a firm commitment from them to make the National Research Cloud a reality showcases a positive step in really making AI something that will empower a lot more people to build solutions for problems that are close to them.
Between the lines: What is particularly heartening is to see someone of Li’s caliber and expertise being a part of the Task Force, especially given the deeply technical nature of the work that will be involved in making this a reality. Additionally, she is someone who is championing human-centered AI through her work at Stanford and elsewhere which hopefully will become a central tenet in the final structure that the National Research Cloud manifests in.

From our Living Dictionary:
“Technosolutionism”
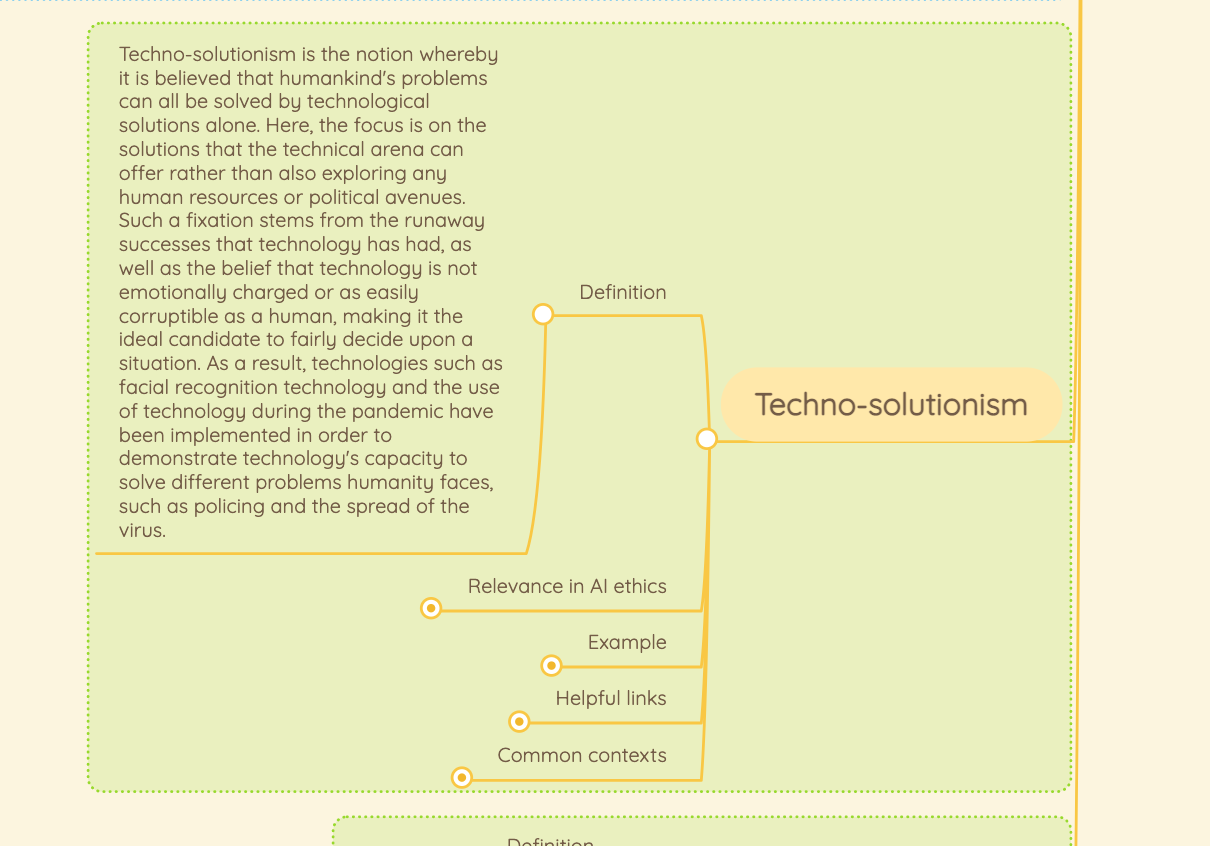
👇 Learn more about why it matters in AI Ethics via our Living Dictionary and expand on the other tabs next to the definition!
From elsewhere on the web:
How data governance technologies can democratize data sharing for community well-being
Our founder Abhishek Gupta is a co-author of this recently published paper.
Data sharing efforts to allow underserved groups and organizations to overcome the concentration of power in our data landscape. A few special organizations, due to their data monopolies and resources, are able to decide which problems to solve and how to solve them. But even though data sharing creates a counterbalancing democratizing force, it must nevertheless be approached cautiously. Underserved organizations and groups must navigate difficult barriers related to technological complexity and legal risk. To examine what those common barriers are, one type of data sharing effort—data trusts—are examined, specifically the reports commenting on that effort. To address these practical issues, data governance technologies have a large role to play in democratizing data trusts safely and in a trustworthy manner. Yet technology is far from a silver bullet. It is dangerous to rely upon it. But technology that is no-code, flexible, and secure can help more responsibly operate data trusts. This type of technology helps innovators put relationships at the center of their efforts.
To delve deeper, read the full paper here.
In case you missed it:
Algorithmic Bias: On the Implicit Biases of Social Technology
The paper presents a comparative analysis of biases as they arise in humans and machines with an interesting set of examples to boot. Specifically, taking a lens of cognitive biases in humans as a way of better understanding how biases arise in machines and how they might be combatted is essential as AI-enabled systems become more widely deployed. What is particularly interesting about the paper is also how the author takes a simple k-nearest neighbor (kNN) approach to showcase how biases arise in practice in algorithmic systems. Also, tackling the hard problem of proxy variables is done through the use of illustrative examples that eschew the overused example of zip codes as a proxy for race. Taking multiple different iterations on the same running example helps to elucidate how biases can crop up in novel ways even when we have made genuine efforts to remove sensitive and protected attributes and made other attempts to prevent biases from seeping into the dataset. Finally, the paper concludes with a call to action for people to closely examine both human and machine biases in conjunction to create approaches that can more holistically address the issues of harm for people who are disproportionately impacted by these systems.
To delve deeper, read the full report here.

Take Action:
Follow us on Twitter and LinkedIn if you haven’t yet - we publish findings from our community engagements, our research work, news on our upcoming programs, funding opportunities, and more!