
AI Ethics Brief #128: Impact of AI art on artists, PET for health data use, scaling spear phishing with LLMs, generative inbreeding, and more.
What are some design considerations that have led to some GenAI applications attracting more users than others?

Welcome to another edition of the Montreal AI Ethics Institute’s weekly AI Ethics Brief that will help you keep up with the fast-changing world of AI Ethics! Every week we summarize the best of AI Ethics research and reporting, along with some commentary. More about us at montrealethics.ai/about.
Support our work through Substack
💖 To keep our content free for everyone, we ask those who can, to support us: become a paying subscriber for the price of a couple of ☕.
If you’d prefer to make a one-time donation, visit our donation page. We use this Wikipedia-style tipping model to support our mission of Democratizing AI Ethics Literacy and to ensure we can continue to serve our community.
This week’s overview:
🙋 Ask an AI Ethicist:
What are some design considerations that have led to some GenAI applications attracting more users than others?
✍️ What we’re thinking:
AI Art and its Impact on Artists
Oppenheimer As A Timely Warning to the AI Community
🤔 One question we’re pondering:
Who should be at the table when discussing AI governance?
🔬 Research summaries:
Selecting Privacy-Enhancing Technologies for Managing Health Data Use
Humans, AI, and Context: Understanding End-Users’ Trust in a Real-World Computer Vision Application
Large Language Models Can Be Used To Effectively Scale Spear Phishing Campaigns
📰 Article summaries:
The Heated Debate Over Who Should Control Access to AI
The AI2 ImpACT License Project: Open, Responsible AI Licenses for the Common Good | AI2 Blog
'Generative inbreeding' and its risk to human culture | VentureBeat
📖 Living Dictionary:
What is a smart city?
🌐 From elsewhere on the web:
Engaging Consumers in a Generative AI World
💡 ICYMI
Bound by the Bounty: Collaboratively Shaping Evaluation Processes for Queer AI Harms
🚨 The Responsible AI Bulletin

We’ve restarted our sister publication, The Responsible AI Bulletin, as a fast-digest every Sunday for those who want even more content beyond The AI Ethics Brief. (Our lovely power readers 🏋🏽, thank you for writing in and requesting it!)
The focus of the Bulletin is to give you a quick dose of the latest research papers that caught our attention in addition to the ones covered here.

🙋 Ask an AI Ethicist:
Every week, we’ll feature a question from the MAIEI community and share our thinking here. We invite you to ask yours and we’ll answer it in the upcoming editions.
Here are the results from the previous edition for this segment:
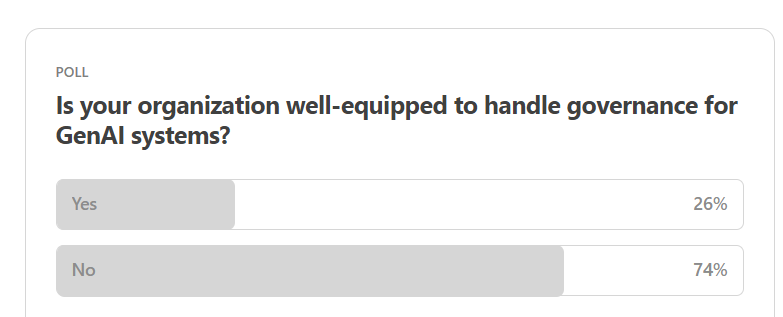
Looking at the results from last week, it is clear that most organizations aren’t yet well-equipped to handle governance, especially given the rapid rise of GenAI.
This past week, a reader asked us, “What are some design considerations that have led to some GenAI applications attracting more users than others?” Thinking about the design of current GenAI systems, some have done better than others, and this might have something to do with how much weight the companies think technological advances (such as SOTA LLMs) have vs. providing better UX and UI to help users achieve their goals with the use of these systems.
For example, since the initial release of ChatGPT, we’ve seen improvements in the UX of the product through the inclusion of chat history that allows you to browse previous conversations with the AI system. Similarly, GenAI chatbot systems in China have made great strides (on the design front) in their product offerings, e.g., including commonly used prompt templates, primed versions of the chatbot (e.g., similar to Character.ai, the chatbot behaves in a particular style), and an internal “social network,” in the case of Baidu, to share and see prompts from other users and the responses they got so that you can level up your own interactions with the system.
While we don’t see all these developments yet in the chatbots from companies in the West, it is worth considering what best practices we can borrow from other countries’ approaches to designing interactions and systems, which brings us to this week’s poll question on the inclusion of China in the upcoming UK AI Safety Summit.
What are the factors that you believe are the most important in convening a global summit to discuss AI governance? Share your thoughts with the MAIEI community:
✍️ What we’re thinking:
AI Art and its Impact on Artists
The last 3 years have resulted in machine learning (ML)-based image generators with the ability to output consistently higher quality images based on natural language prompts as inputs. As a result, many popular commercial “generative AI Art” products have entered the market, making generative AI an estimated $48B industry. However, many professional artists have spoken up about the harms they have experienced due to the proliferation of large scale image generators trained on image/text pairs from the Internet. In this paper, we review some of these harms which include reputational damage, economic loss, plagiarism and copyright infringement. To guard against these issues while reaping the potential benefits of image generators, we provide recommendations such as regulation that forces organizations to disclose their training data, and tools that help artists prevent using their content as training data without their consent.
To delve deeper, read the full article here.
Oppenheimer As A Timely Warning to the AI Community
Like many others, the author went to the cinema to watch Oppenheimer on the opening Friday night. And, like many others in my screening, the author left quiet, absorbed, and reflective. Haunted by the birth of the nuclear bomb and Oppenheimer’s regret and mourning as he quotes, “Now I am become Death, the destroyer of worlds.” In the bathroom queue, the author overheard a woman saying, “I left that movie feeling grateful that I will never have to carry that weight.” Others agreed. The author stayed quiet, scared that, as an early career researcher of machine ethics, they may at some point have to carry the weight of knowing that they have, in some way, contributed to the creation of something which cannot be undone.
To delve deeper, read the full article here.
🤔 One question we’re pondering:
This past week, we’ve been occupied with trying to figure out how to meaningfully address the question of “Who should be at the table when discussing AI governance?” In particular, we’ve seen that meetings tend to skew heavy one way or the other (technical, policymaking, or business) and some multidisciplinary forums try to bring all these stakeholders together, but the effort fizzles out beyond the convening. Have you come across good instances where such efforts have been successful? And if so, what were the characteristics that led to that success?
We’d love to hear from you and share your thoughts back with everyone in the next edition:

🔬 Research summaries:
Selecting Privacy-Enhancing Technologies for Managing Health Data Use
In the 21st century, real-world data privacy is possible using privacy-enhancing technologies (PETs) or privacy engineering strategies. This paper draws on the literature to summarize privacy engineering strategies that have facilitated the use and exchange of health data across various practical use cases.
To delve deeper, read the full summary here.
Humans, AI, and Context: Understanding End-Users’ Trust in a Real-World Computer Vision Application
Trust is a key factor in human-AI interaction. This paper provides a holistic and nuanced understanding of trust in AI by describing multiple aspects of trust and what factors influenced each in a qualitative case study of a real-world AI application.
To delve deeper, read the full summary here.
Large Language Models Can Be Used To Effectively Scale Spear Phishing Campaigns
Large language models (LLMs) like ChatGPT can be used by cybercriminals to scale spear phishing campaigns. In this paper, the author demonstrates how LLMs can be integrated into various stages of cyberattacks to quickly and inexpensively generate large volumes of personalized phishing emails. The paper also examines the governance challenges created by these vulnerabilities and proposes potential solutions; for example, the author suggests using other AI systems to detect and filter out malicious phishing emails.
To delve deeper, read the full summary here.

📰 Article summaries:
The Heated Debate Over Who Should Control Access to AI
What happened: In May, the CEOs of prominent AI labs, including OpenAI, Google DeepMind, and Anthropic, warned about the risks associated with AI, likening it to the dangers of pandemics and nuclear war. They advocated restricting access to powerful AI models to prevent misuse, particularly by malicious actors who might use them for disinformation or cyberattacks. However, Meta took a different approach and recently released the Code Llama family of AI models, including their flagship Llama 2, which competes with OpenAI's GPT-4 capabilities. Meta makes these models freely available, contrasting with other AI developers who offer limited, paid access to their models to prevent misuse and generate revenue.
Why it matters: Meta's stance on open access to AI models diverges from industry norms. They initially faced criticism when their LLaMa model's weights were leaked online, prompting concerns about ethical considerations. The debate over controlling AI access has broader implications, with prominent AI companies and national security experts advocating for restrictions. At the same time, Meta, “and many progressives, libertarians, and old-school liberals,” argue for open AI development. Meta claims this approach fosters innovation and safety through community-driven problem-solving. However, critics argue that Meta still benefits commercially and that open sourcing might not be the safest route for AI development.
Between the lines: The E.U. AI Act, currently in legislative progress, aims to establish safety standards for "foundation models," including those like Llama 2 and GPT-4. While it doesn't impose a licensing regime, it may hinder open-sourcing in other ways, affecting large companies like Meta and smaller open-source developers. While larger companies may find compliance manageable, smaller organizations could see reduced liabilities. Some organizations have proposed recommendations to support open-source AI development under this act. The underlying question is who should have agency in shaping technology, with competing views on whether to trust company-driven innovation or embrace democratic processes with more visibility.
The AI2 ImpACT License Project: Open, Responsible AI Licenses for the Common Good | AI2 Blog
What happened: The pervasive presence of AI is evident in smartphones, healthcare, automobiles, and workplaces. The rapid adoption of AI technologies presents potential benefits and significant challenges, including the proliferation of potentially harmful AI applications and their availability to malicious actors. Regulatory efforts like the EU AI Act are being considered to address these issues. However, the urgency of the challenges and documented risks associated with AI demand immediate solutions. AI2, an institution engaged in fundamental AI research, is exploring practical measures, such as licenses, to mitigate risks and promote responsible AI use.
Why it matters: AI2 is introducing AI2 Impact Licenses focusing on their AI2 OLMo (Open Language Model) project. These licenses are designed with a risk-based approach, recognizing that the potential impact, whether positive or negative, of an AI artifact is not solely determined by its type. This approach differs from traditional artifact-based licensing and aims to better align with the varying degrees of harm associated with different AI artifacts. The licenses also emphasize the importance of community norms as a complement to legal measures, incorporating risk-based terms, behavioral restrictions, public disclosure of license violations, and the publication of the use and impact of derivative works derived from licensed artifacts.
Between the lines: The AI2 Impact Licenses introduce two innovative elements. Firstly, they prioritize a risk-based approach over an artifact-based one, aligning more closely with potential regulatory structures. Secondly, they allow for public reporting of violators and impose disclosure requirements regarding intended use and project inputs. This approach underscores the significance of transparency in AI development, incentivizing developers to be transparent and accountable for their AI applications. AI2 aims to contribute to the public's understanding of AI by committing to accountability, collaboration, and transparency, which includes sharing the inputs that drive their AI research and subjecting themselves to public scrutiny in cases where responsible AI standards are not met.
'Generative inbreeding' and its risk to human culture | VentureBeat
What happened: Inbreeding, when individuals in a population reproduce with genetically similar members, can lead to health problems and deformities due to the expression of recessive genes. This phenomenon is becoming a concern in the field of generative AI, where AI systems are at risk of training on datasets that contain AI-generated content, corrupting the "gene pool" of human culture. This issue may escalate as newer AI systems train on distorted artifacts, creating copies of copies of human culture.
Why it matters: "Generative Inbreeding" in AI poses two significant problems. Firstly, it can degrade AI systems, causing them to produce increasingly poor-quality content over time, akin to making copies of copies. Secondly, it distorts human culture by introducing deformities into our cultural heritage that do not accurately represent our collective sensibilities. Additionally, a recent U.S. federal court ruling stating that AI-generated content cannot be copyrighted may lead to AI artifacts surpassing human-created content in influence.
Between the lines: Two potential solutions to the inbreeding problem are emerging. One involves AI systems that distinguish generative content from human content, but it's proving more challenging than expected. Another solution is embedding "watermarking" data into generative artifacts to identify fakes and prevent cheating. However, even if the inbreeding issue is resolved, reliance on AI could stifle human culture.

📖 From our Living Dictionary:

👇 Learn more about why it matters in AI Ethics via our Living Dictionary.
🌐 From elsewhere on the web:
Engaging Consumers in a Generative AI World
Advances in generative AI have brought the internet to an inflection point. In the not-too-distant future, large language model (LLM)-powered virtual assistants could become a universal gateway to the internet. For company leaders, this will mean making fundamental choices about how they engage with consumers.
On one side of the spectrum, companies will be able to relinquish control of their consumer interface to an LLM-powered virtual assistant (or other conversational AI) using APIs such as plug-ins. OpenAI’s ChatGPT plug-in enables consumers to make meal reservations and order groceries via third-party sites like OpenTable and Instacart; other LLM providers are likely to follow suit.
At the other end, companies can retain control of their interface with a custom generative AI model on their own website and app. The implementation will vary, with companies choosing to build or fine-tune. Bloomberg built its own model that it plans to integrate into its services and features. Expedia incorporated OpenAI’s model into its own application—users stay on the company’s site but plan trips using ChatGPT.
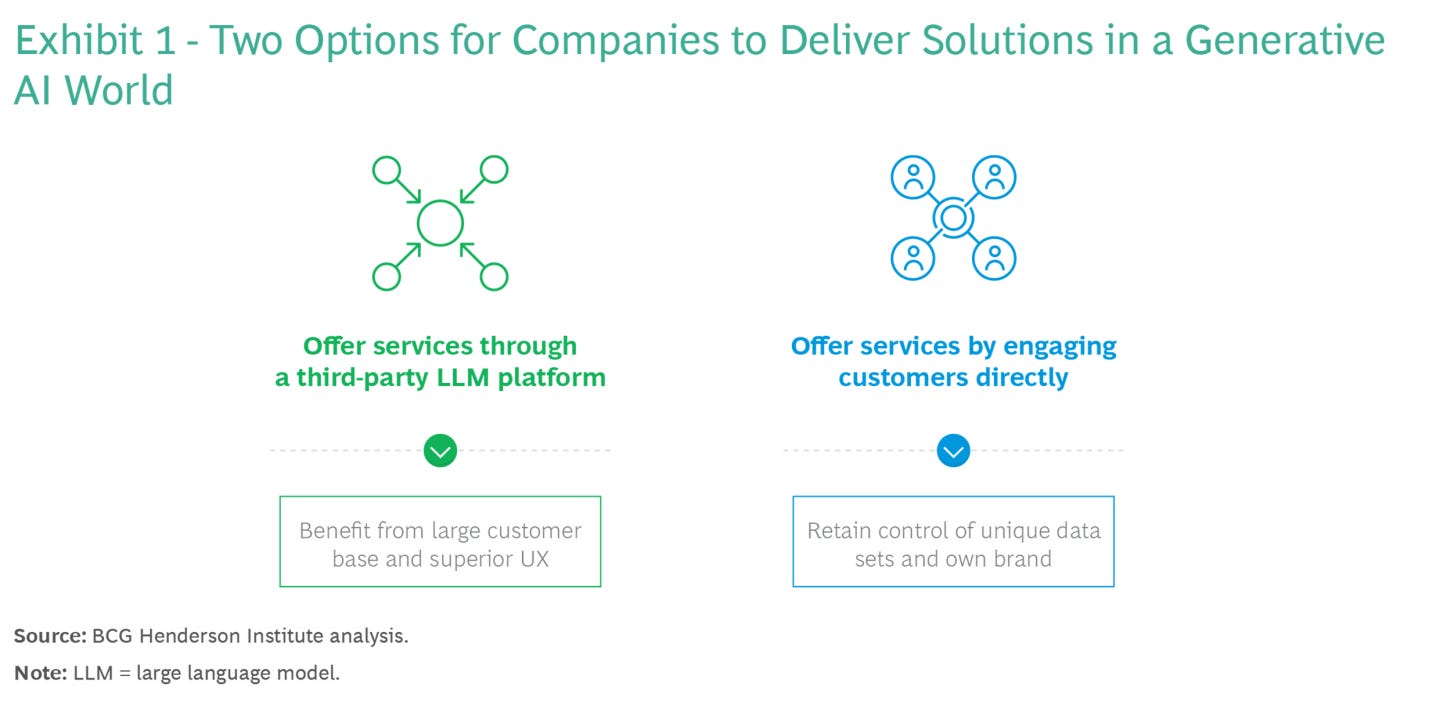
Both strategies—relinquish and retain—have benefits and risks. And the benefit of one option is often a risk of the other. It is also likely that various options will be beneficial for different use cases, based on specific needs and risk tolerance. We’ve researched these evolving market dynamics to offer insight into choosing among and activating each strategy. (See Exhibit 1.) Now is the time to do so—before the future is defined by early movers.
To delve deeper, read the full article here.
💡 In case you missed it:
Bound by the Bounty: Collaboratively Shaping Evaluation Processes for Queer AI Harms
AI systems are increasingly being deployed in various contexts; however, they perpetuate biases and harm marginalized communities. An important mechanism for auditing AI is allowing users to provide feedback on systems to the system designers; an example of this is through “bias bounties,” that reward users for finding and documenting ways that systems may be perpetuating harmful biases. In this work, we organized a participatory workshop to investigate how bias bounties can be designed with intersectional queer experiences in mind; we found that participants’ critiques went far beyond how bias bounties evaluate queer harms, questioning their ownership, incentives, and efficacy.
To delve deeper, read the full article here.

Take Action:
We’d love to hear from you, our readers, on what recent research papers caught your attention. We’re looking for ones that have been published in journals or as a part of conference proceedings.
DAIR https://www.dair-institute.org/
Paige Lord (AI Ethicist, younger female, experienced tech worker and manager, consultant). Dr. Don Nations (professor, professional coach, part of the startup ecosystem [including companies finding ways to integrate AI into their products and services], theologian, educator, DEI certified). Rachael Woods of The AI Exchange (AI implementation specialist, consultant to businesses on how to integrate AI into their workflows, younger female, experienced tech worker).