
AI Ethics Brief #137: RAI-by-design taxonomy for FMs, anthropomorphization of AI, changing value of human skills, and more.
Will there be reconciliation between open- vs. closed-source foundation model approaches in 2024?

Welcome to another edition of the Montreal AI Ethics Institute’s weekly AI Ethics Brief that will help you keep up with the fast-changing world of AI Ethics! Every week, we summarize the best of AI Ethics research and reporting, along with some commentary. More about us at montrealethics.ai/about.
Support our work through Substack
💖 To keep our content free for everyone, we ask those who can, to support us: become a paying subscriber for the price of a couple of ☕.
If you’d prefer to make a one-time donation, visit our donation page. We use this Wikipedia-style tipping model to support our mission of Democratizing AI Ethics Literacy and to ensure we can continue to serve our community.
This week’s overview:
🙋 Ask an AI Ethicist:
Will there be reconciliation between open- vs. closed-source foundation model approaches in 2024?
✍️ What we’re thinking:
Bridging the intention-action gap in the Universal Guidelines on AI
🤔 One question we’re pondering:
How should we tackle the tradeoffs required in resource allocation for Responsible AI program implementation?
🪛 AI Ethics Praxis: From Rhetoric to Reality
How should we prioritize for a (potential) hierarchy in ethical AI principles?
🔬 Research summaries:
A Taxonomy of Foundation Model based Systems for Responsible-AI-by-Design
Talking About Large Language Models
Anthropomorphization of AI: Opportunities and Risks
📰 Article summaries:
The Beatles’ final song is now streaming thanks to AI - The Verge
How will artificial intelligence change the value of human skillsets?
How to Prepare for a GenAI Future You Can’t Predict
📖 Living Dictionary:
What is an example of a griefbot?
🌐 From elsewhere on the web:
The carbon conundrum and ethical quandaries in the expanding realm of AI
💡 ICYMI
A roadmap toward empowering the labor force behind AI
🚨 AI Ethics Praxis: From Rhetoric to Reality
Aligning with our mission to democratize AI ethics literacy, we bring you a new segment in our newsletter that will focus on going beyond blame to solutions!
We see a lot of news articles, reporting, and research work that stops just shy of providing concrete solutions and approaches (sociotechnical or otherwise) that are (1) reasonable, (2) actionable, and (3) practical. These are much needed so that we can start to solve the problems that the domain of AI faces, rather than just keeping pointing them out and pontificate about them.
In this week’s edition, you’ll see us work through a solution proposed by our team to a recent problem and then we invite you, our readers, to share in the comments (or via email if you prefer), your proposed solution that follows the above needs of the solution being (1) reasonable, (2) actionable, and (3) practical.

🙋 Ask an AI Ethicist:
Every week, we’ll feature a question from the MAIEI community and share our thinking here. We invite you to ask yours, and we’ll answer it in the upcoming editions.
Here are the results from the previous edition for this segment:
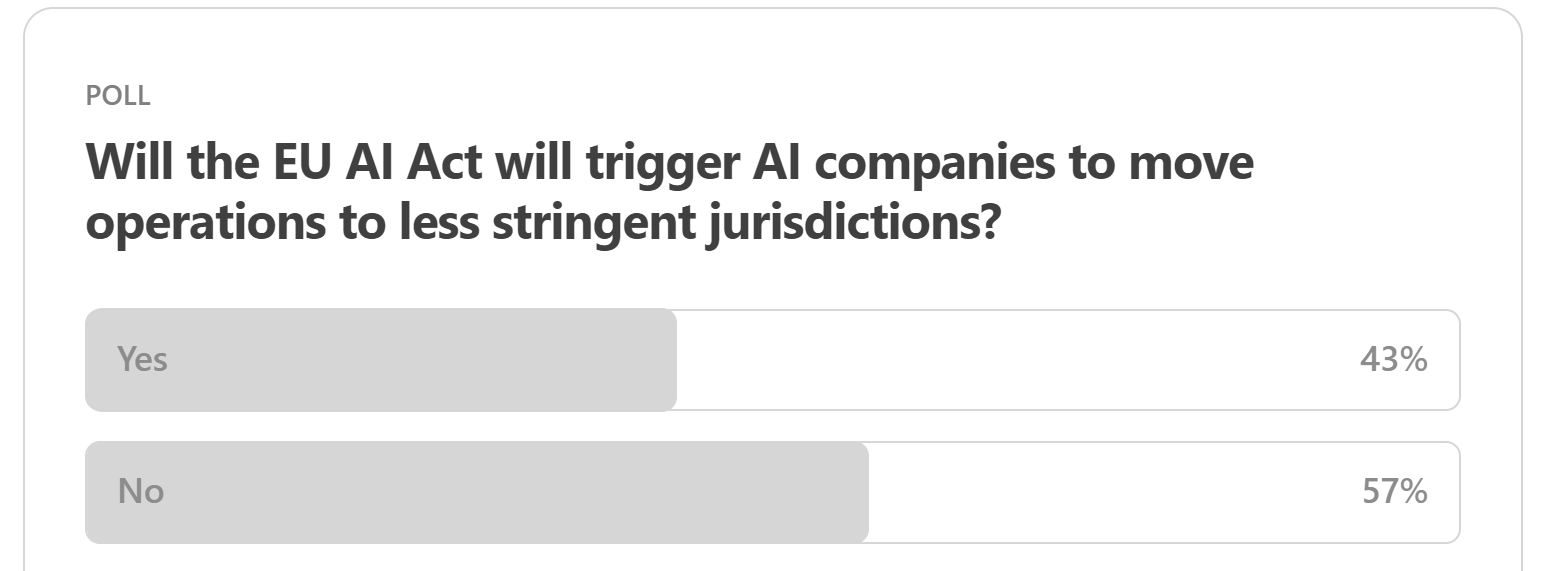
Well, this one has a narrow edge emphasizing that companies might still continue to build in Europe, despite some of the EU AI Act requirements that will come into force soon. Aside from Germany’s Aleph Alpha and France’s Mistral, what are some other organizations that have caught your attention from the European AI ecosystem?
One of our readers, Mohammed R., wrote in to ask if the fragmentation of the AI ecosystem into those who are pushing for closed-source models (e.g., those that are exposing foundation models via APIs) vs. open-source models (e.g., downloadable on HuggingFace) will be something that will have some reconciliation in 2024 or is this a hard fork?
The fragmentation of the AI ecosystem into open-source and closed-source models is a complex issue with no clear resolution in sight for 2024. Both models have their advantages and disadvantages, and the debate is ongoing among AI developers, companies, and regulators.
Open-source AI models, such as those downloadable on HuggingFace, offer increased model flexibility, customizability, and transparency. They also foster accelerated innovation due to the large developer community involved. However, there are concerns that open-source AI could be misused, leading to issues like cyberattacks or AI-generated hate speech.
On the other hand, closed-source models, often exposed via APIs, can offer a performance edge, additional development resources, and greater support from the companies that developed them. However, they also risk centralizing control of powerful AI capabilities in the hands of a few, which could lead to dystopian outcomes.
There are suggestions for a middle ground approach, such as a "Regulated Source AI Development Model", which aims to take the best of both open and closed-source models while avoiding their respective failure modes. This model would establish a regulated space between the more extreme open and closed-source models.
In the current landscape, big tech companies like Meta have launched open-source large language models, while others like Google and OpenAI have taken closed approaches. The private large language model (LLM) developer market is also split.
The future of this dichotomy is uncertain. Some believe that open-source AI will continue to grow in popularity as startups and tech giants seek to compete with incumbent market leaders. Others suggest that there could eventually be an open-source distributed networking system that average users could contribute processing power to, helping to solve larger models.
How would you go about navigating this in 2024? Share your thoughts with the MAIEI community:
✍️ What we’re thinking:
Bridging the intention-action gap in the Universal Guidelines on AI
The Universal Guidelines on AI (UGAI) from the CAIDP are comprehensive in the intentions that one must embody when it comes to designing, developing, deploying, and maintaining AI systems. Their timelessness and relevance are a testament to this comprehensiveness, with many other initiatives coming later on borrowing from the strong foundations set forth in that proposal. Yet, the guidelines were conceived in the early days of Responsible AI, i.e., when discussions weren’t as mainstream as they are in 2023. Five years is a long time in the world of technology, more so in the world of AI. With the recent frothy ecosystem of Generative AI, we have seen a strong impetus for adopting these technologies, often with Responsible AI playing second fiddle to business and functional objectives. We are now firmly in a world where organizations are beginning to see returns from their investments in AI adoption within their organizations. At the same time, they are also experiencing growing pains, such as the emergence of shadow AI, that raises cybersecurity concerns. While useful as a North Star, guidelines need accompanying details that help implement them in practice. Right now, we have an unmitigated intention-action gap that needs to be addressed - it can help strengthen the UGAI and enhance its impact as organizations adopt this as their de facto set of guidelines.
To delve deeper, read the full article here.
🤔 One question we’re pondering:
One of the questions that has been bouncing around in the staff’s heads is how to square the resource demands for implementing Responsible AI within an organization? In particular, we keep running into scenarios where the organization is interested in implementing a Responsible AI program but has very little idea and sometimes no planned commitment for dedicating resources towards the implementation of that program. How should we navigate this challenge?
We’d love to hear from you and share your thoughts with everyone in the next edition:
🪛 AI Ethics Praxis: From Rhetoric to Reality
For those of us who are more on the applied-end of the spectrum of Responsible AI, sometimes we are asked if there is a hierarchy to how we should prioritize ethical AI principles?
We’ve found the following as a useful rank-ordering to answer that question, keeping in mind the organizational context and application domain for the person/organization asking this of us:
Safety and Security: Ensuring the AI system is safe and secure should be the top priority. This involves protecting against unintended consequences, ensuring reliability, and safeguarding against misuse and malicious attacks.
Transparency and Explainability: The AI system should be transparent and its decisions or outputs should be explainable to the end-users. This helps in building trust and understanding, and is crucial for accountability.
Fairness and Non-discrimination: The AI should be designed to avoid biases and should not discriminate based on race, gender, or other characteristics. This is essential for ethical and legal compliance and for the system's societal acceptance.
Privacy and Data Governance: Respecting the privacy of individuals and properly managing the data the AI system uses and generates is crucial. This includes compliance with data protection laws and ethical standards for data use.
Beneficence and Non-maleficence: The AI system should aim to do good and not harm individuals or society. This means considering the broader impacts of the AI system on society and the environment.
User Autonomy and Control: Users should have control over how AI systems impact them, and their autonomy should be respected. This includes giving users the ability to opt-out or control how their data is used.
Accountability and Responsibility: There should be clear accountability and responsibility for the AI system's actions. This involves having mechanisms in place to identify and rectify mistakes or misuse.
Societal and Environmental Well-being: Finally, consider the long-term impacts of AI on society and the environment. This principle ensures that AI contributes positively to the broader societal goals and environmental sustainability.
It's important to note that these principles are interrelated and often overlap. The prioritization might vary based on the specific use case, the stakeholders involved, and the societal context. The key is to have a flexible approach that can adapt to different situations while ensuring that all these principles are considered in the AI system's lifecycle.
You can either click the “Leave a comment” button below or send us an email! We’ll feature the best response next week in this section.

🔬 Research summaries:
A Taxonomy of Foundation Model based Systems for Responsible-AI-by-Design
As foundation models are in their early stages, the design of foundation model-based systems has not yet been systematically explored. There is little understanding of the impact of introducing foundation models in software architecture. This paper proposes a taxonomy of foundation model-based systems, which classifies and compares the characteristics of foundation models and design options of foundation model-based systems. The taxonomy comprises three categories: foundation model pretraining and fine-tuning, architecture design of foundation model-based systems, and responsible-AI-by-design.
To delve deeper, read the full summary here.
Talking About Large Language Models
The words we use to talk about current large language models (LLMs) can amplify the tendency to see them as human-like. Yet LLM-based dialogue agents are so fundamentally different from human language users that we cannot assume their behavior will conform to normal human expectations. So while it is natural to use everyday psychological terms like “believes,” “knows,” and “thinks” in the context of these systems, we should do so with caution and avoid anthropomorphism.
To delve deeper, read the full summary here.
Anthropomorphization of AI: Opportunities and Risks
The rise of generative AI has enabled companies and developers to customize their conversational agents by assigning them personas. While this is crucial for utility and controls the flow of significant capital, it leads to users anthropomorphizing the chatbots to a significantly larger degree. In this work, we discuss anthropomorphization’s legal and philosophical implications and advocate a cautious approach toward personalization.
To delve deeper, read the full summary here.

📰 Article summaries:
The Beatles’ final song is now streaming thanks to AI - The Verge
What happened: The Beatles released their first new song since 1995, titled "Now and Then," utilizing breakthrough technology and machine learning. Paul McCartney and Ringo Starr used an old lo-fi John Lennon recording, facing challenges due to technical issues with the original tape. Progress on the song stalled until director Peter Jackson, working on the Get Back documentary, developed a technology to separate music components using machine learning. This allowed McCartney and Starr to revisit and complete "Now and Then," recording additional tracks and achieving the ending the song deserved.
Why it matters: The release of "Now and Then" is significant as it represents the first new Beatles song in decades, showcasing the band's adaptation to cutting-edge technology. Using machine learning to salvage an old recording reflects a commitment to preserving and enhancing the Beatles' musical legacy. Despite concerns from fans, the project received approval from all involved parties, including the estates of nonliving members.
Between the lines: Sean Ono Lennon and Paul McCartney expressed admiration for the experimental use of recording technology, with McCartney noting the beauty of still working on Beatles music in 2023. The completion of "Now and Then" is described as possibly the last Beatles song, adding emotional significance to the project. Using state-of-the-art technology opens possibilities for restoring other recordings, suggesting an avenue for breathing new life into historical music beyond the Beatles' catalog.
How will artificial intelligence change the value of human skillsets?
What happened: Generative artificial intelligence is gaining attention for its potential to automate tasks and reduce costs in various industries. Studies, including one published in March, suggest that large language models like ChatGPT could impact a significant portion of the US workforce, with potential effects on tasks ranging from 10% to 50%. Despite concerns about job displacement, some experts, such as Stanford University professor Erik Brynjolfsson, argue that generative AI might not shrink the job market but could instead create new roles and foster human-AI collaboration.
Why it matters: While the introduction of generative AI raises concerns about job displacement, studies indicate positive impacts on productivity. Deploying generative AI in customer service centers, for example, led to a 14% boost in employee productivity, with less experienced staff benefiting the most. The study suggests that the most productive use of generative AI involves augmentation rather than imitation or replacement of human roles. The emphasis on augmenting human capabilities with AI could create new roles and increase efficiency across various industries.
Between the lines: As generative AI becomes more prevalent, new roles are emerging to support its growth. For example, a new role called the "prompt engineer" is emerging, focusing on testing and developing text prompts to elicit accurate and desirable responses from AI applications. The importance of asking the right questions and understanding customer problems is highlighted, emphasizing the need for employees to embrace creativity and use AI tools effectively. The evolving job landscape in the AI era includes opportunities for specialized roles, challenging the perception of certain tasks as cheap labor and potentially leading to outsourcing to other countries.
How to Prepare for a GenAI Future You Can’t Predict
What happened: Since last November, executives across various industries, including insurance, manufacturing, and pharmaceuticals, have been exploring ways to create more value with fewer human resources. The viral success of ChatGPT demonstrated the potential for AI to generate content such as emails, essays, and financial reports. Goldman Sachs predicts that generative AI could eliminate or significantly diminish 300 million jobs within the decade. Motivated by AI possibilities, concerns about finding skilled workers, and recent market challenges, business leaders envision a future with fewer human employees. Still, this perspective is viewed as a significant miscalculation.
Why it matters: The rush towards AI-driven automation is premature, given the uncertainties surrounding the future of AI and its potential impact on various job sectors. The focus on immediate gains overlooks the broader transformation that AI will bring to entire business segments, similar to the unforeseen consequences of the early internet era. Leaders must adopt a more strategic and forward-thinking approach, acknowledging that AI and human workforces will coexist and evolve unpredictably. To navigate this landscape, leaders should prioritize workforce evolution, skill development, and evidence-backed scenarios that challenge conventional thinking.
Between the lines: Workforce change is an inevitable outcome of technological evolution, especially with the advancements in generative AI. Leaders need a systematic approach to anticipate how and when their workforce must adapt to leverage AI effectively. The key is not making long-range predictions but positioning organizations to be ready for anything as AI continues to improve. Organizations should methodically plan for the future, understand AI's limitations and strengths, foster a culture of continual evaluation, and resist the temptation to reduce the workforce. Instead, strategic foresight should be used to create a future where AI complements a highly skilled workforce, fostering more productive and creative collaboration between humans and AI.

📖 From our Living Dictionary:
What is an example of a griefbot?

👇 Learn more about why it matters in AI Ethics via our Living Dictionary.
🌐 From elsewhere on the web:
The carbon conundrum and ethical quandaries in the expanding realm of AI
AI systems require significant computational resources for various tasks such as training, hyperparameter optimization, and inference. They rely on vast amounts of data, often requiring specialized hardware and data center facilities, consuming electricity and contributing to carbon emissions. The substantial carbon footprint raises concerns about environmental sustainability and social justice implications.
As AI models continue to grow in size, the pace of compute consumption is increasing exponentially. For instance, high-compute AI systems have doubled their consumption every 3.4 months, and this rate may even be faster now. Despite the rapid increase in computational requirements, the improvements in performance achieved by these large-scale AI models are only marginal. Moreover, large-scale AI models introduce challenges such as biases, privacy concerns, vulnerability to attacks, and high training costs.
These challenges are compounded by the fact that the models are widely accessible through public application programming interfaces (APIs), limiting the ability to address the problems downstream (for those wondering, making large-scale AI models accessible through public APIs amplifies the risk of widespread bias and errors due to their extensive use, limited user control, and potential privacy breaches, and raises concerns about security vulnerabilities, scalability costs, and ethical challenges across diverse applications and user groups).
To delve deeper, read the full article here.
💡 In case you missed it:
A roadmap toward empowering the labor force behind AI
Over the past few months, the public has learned something about AI that those of us in the field have known for a long time: Hundreds of millions of people around the world effectively have uncompensated side gigs generating content for AI models, often models owned by some of the richest companies in the world. Despite its vital role as “data labor” for these AI models, the public rarely has the ability to shape how these AI systems are used and who profits from them. This paper outlines steps that policymakers, activists, and researchers can take to establish a more labor-friendly data governance regime and, more generally, empower the data producers who make AI possible.
To delve deeper, read the full article here.

Take Action:
We’d love to hear from you, our readers, on what recent research papers caught your attention. We’re looking for ones that have been published in journals or as a part of conference proceedings.
"One of the questions that has been bouncing around in the staff’s heads is how to square the resource demands for implementing Responsible AI within an organization? In particular, we keep running into scenarios where the organization is interested in implementing a Responsible AI program but has very little idea and sometimes no planned commitment for dedicating resources towards the implementation of that program. How should we navigate this challenge?"
Unfortunatly, showcasing from a moral standpoint that it's just the right thing to do isn't enough. The angle to take is to make executives realize the concrete and strategical benefits of implementing Responsible AI for their organization. To do this, one should start with building and creating company ethics guidelines, and then implementing them.
We can look at this from the lens of performativity.
The following ideas are taken from this amazing Mooc on AI and ethics https://ethics-of-ai.mooc.fi/chapter-7/2-ethics-as-doing. I'll summarize and quote some passages below:
"[...] performativity is the capacity of words to do things in the world. That is, sometimes making statements does not just describe the world, but also performs a social function beyond describing. As an example, when a priest declares a couple to be “husband and wife”, they are not describing the state of their relationship. Rather, the institution of marriage is brought about by that very declaration – the words perform the marrying of the two people."
Similarly, ethics guidelines can serve as performative texts:
"Guidelines as assurances:
Others have argued that ethics guidelines work as assurance to investors and the public (Kerr 2020). That is, in the age of social media, news of businesses’ moral misgivings spread fast and can cause quick shifts in a company’s public image. Publishing ethics guidelines makes assurances that the organization has the competence for producing ethical language, and the capacity to take part in public moral discussions to soothe public concern.
Thus AI ethics guidelines work to deflect critique away from companies; from both investors and the general public. That is, if the company is seen as being able to manage and anticipate the ethical critique produced by journalists, regulators and civil society, the company will also be seen as a stable investment, with the competence to navigate public discourses that may otherwise be harmful for its outlook."
"Guidelines as expertise:
With the AI boom well underway, the need for new kinds of expertise arises, and competition around ownership of the AI issue increases. That is, the negotiations around AI regulation, the creation of AI-driven projects of governmental redesign, the implementation of AI in new fields, and the public discourse around AI ethics in the news all demand expertise in AI and especially the intersection of AI and society.
To be seen as an expert yields certain forms of power. Being seen as an AI ethics expert gives some say in what the future of society will look like. Taking part in the AI ethics discussion by publishing a set of ethical guidelines is a way to demonstrate expertise, increasing the organization’s chances of being invited to a seat at the table in regards to future AI issues."
The above implies massive benefits for a company if properly done and communicated. Not only is it the right thing to do in the face of increasingly ubiquitous and capable AI, but it is in my view a indispensable strategic advantage to focus on.
But just talk isn't enough. To truely cement oneself as an trustworthy expert and to not fall into the trap of ethics washing, one needs to also implement the guidelines in a way where tangible changes are made to the way the company is doing AI. This will reinforce what was mentioned above.
Then, the company can start implementing some of the great practical things you have suggested in the previous newsletter which will be easier to do once a ethics team is in place.
Just some thoughts.
I love that you are thinking about how to make ethics more practical. I'm taking notes and researching that myself too. I've also been wondering what the best approaches could be to get more people interested and involved in ethics and to not just focus on the techincal aspects. From my POV this is more of a challenge with applied AI practitionners than researchers.
There is another worry with respect to open sourcing large language models. It stems from the view that their research in general, needs to slow down or be halted. This is because there are risks involved in continuing to roll out increasingly capable models and features, all the while our understanding of these models are very limited. We currently don't know how to align the models in a way where they won't kill us once they are smart enough. Since we only have 1 go at tackling this problem, we need much more time and research.
Therefore, open sourcing models will ultimately accelerate LLM development and make it harder to regulate and put any risk prevention guardrails in place. In doing so, we'd simply be accelerating out extinction.
This is a view that Eliezer Yudkowsky for instances, but also many others hold (simplifying and his view is much more nuanced and well put together than my summary attempt).
I personally think that the more researchers are thinking about the problem, the better. Progress and decisions around LLMs shouldn't be limited to a few companies. While the risks mentioned above are real, I believe that we need the community as a whole to be thinking and working on how to implement safe AI. Also, the current market incentives are such that top tech companies are prone to ethics washing. They'll be more inclined to release models before any serious testing is done in order to capture more market share and establish themselves in the future.
Ultimately it is a super difficult ethical and moral problem that I am only starting to wrap my head around. I'm still very uncertain about which option is better between close vs open source models.
Thank you for your work and promoting discussions around this topic.